RAG (Retrieval-augmented Generation) is only as good as the retrieval. If retrieval fails, the LLM will either still make up an answer (and possibly hallucinate), or simply not be able answer the question. For example, ChatGPT (in its latest 4o version and using web search) is very good in providing reasonable answers to questions about current events – such as a road closure due to construction work. It will also provide a reasonable answer if asked for feedback of affected travelers. The problem: if asked to provide actual statements or at least the sources for travelers’ feedback, it is very likely to fail and thereby reveal that the answer to the previous question actually was made up.
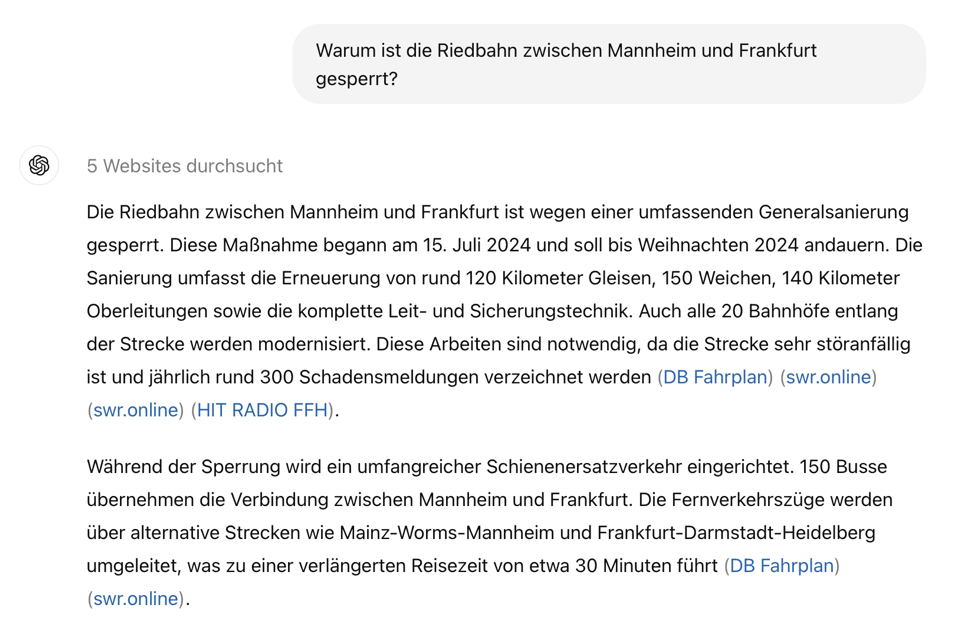
Source: chatgpt.com
Standard web search is optimized to factual information (in this case about the road closure). It does rarely reveal customer feedback or actual reactions. In consequence, one must turn to other (social) channels like X (Twitter) or Facebook. However, these sources have another disadvantage: they carry very noisy information – making it difficult to filter relevant and meaningful feedback. This is where arguments come into play: they “express evidence or reasoning that can be used to either support or oppose a given topic” [1].
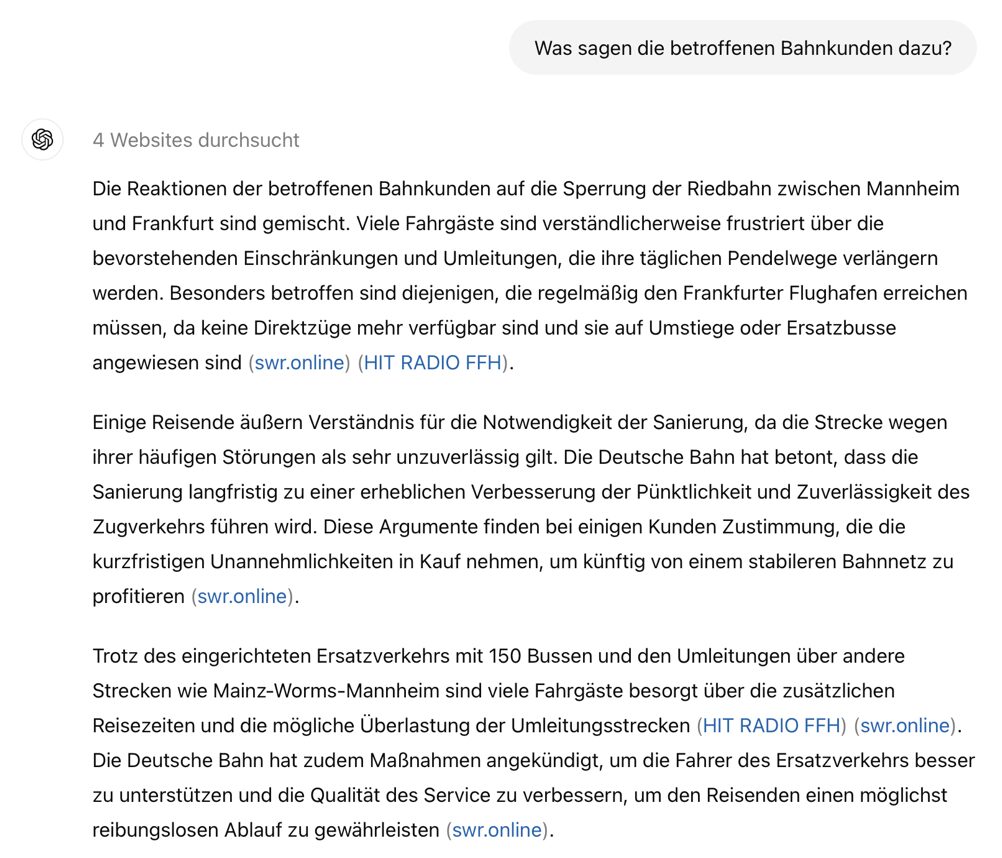
Source: chatgpt.com
However, argument retrieval itself is also difficult. More difficult than other kinds of search like News Retrieval or even Question-Answering [2] as it requires a deeper semantic and discourse understanding. Neural retrieval models — which achieve state-of-the-art performance on many retrieval tasks [3] — fare even worse than good old BM25 (basically, keyword-based search).
We are working hard to solve this problem. Meanwhile, our approach to apply argument mining (and, optionally, argument clustering), before RAG solves all the above problems through a 3-step approach:
1. Use simple or semantic search to identify relevant content (e.g. for questions on road closure, including from social media),
2. apply argument mining to the identified content (usually filters out 90-95% of the data), and
3. apply RAG with semantic search on the arguments to answer the actual question.
For details on the 3rd step, please refer to one of our previous posts on RAG. https://www.summetix.com/enhancing-retrieval-augmented-generation-with-argument-mining-a-paradigm-shift-in-ai/
We hope that you enjoyed this post, please share your thoughts or ask any questions in the comments.
References and further reading:
[1] Stab et al. (2018): Cross-topic Argument Mining from Heterogeneous Sources (https://aclanthology.org/D18-1402.pdf)
[2] Thakur et al. (2024): Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR (https://downloads.webis.de/publications/papers/thakur_2024.pdf)
[3] Thakur et al. (2021): BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. (https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/65b9eea6e1cc6bb9f0cd2a47751a186f-Paper-round2.pdf)